MIT 6.S081 - Lab Lock - overview
在做实验之前,阅读 xv6手册 的以下章节及相关源代码:
- [1] xv6 book, Chapter 6 Locking (锁)
- [2] xv6 book, 3.5 Code: Physical memory allocator(物理内存分配器)
- [3] xv6 book, Chapter 8 File system:8.1 Overview ~ 8.3 Code: Buffer cache(磁盘缓存)
起始
首先回答报告的问题吧,算是大致浏览实验指导书的结果。但是千万不要觉得他把什么都告诉你了,然后你就能凭借这些知识去写了。
很好的指导书,爱来自瓷器(.jpg
即使你知道优化方法,但你对内存、锁和磁盘内存仅限于指导书告诉你的部分,那你还是很难写好这个实验的,所以还是要去看书。
PLUS:就算看了也不一定马上就能很好理解,还要多问问同学、老师和助教。
结束:报告
一 回答问题
1 内存分配器
a. 什么是内存分配器?它的作用是?
(这里是什么和为什么应该能一块回答)
这次实验涉及到的应该是物理内存分配器,其所有功能都在 kernel/kalloc.c 中。分配器把物理内存划分成 4KB 大小的页帧来管理,并为调用它的进程提供分配内存和回收内存的方法。
b. 内存分配器的数据结构是什么?它有哪些操作(函数),分别完成了什么功能?
数据结构:
struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;分配器的核心数据结构是由空闲物理页组成的链表 freelist,这个空闲页链表将物理内存划分成4KB大小的页帧来管理,并使用 自旋锁 (spinlock)进行保护。每个空闲页在链表里都是 struct run next 指向下一个空闲物理页。
函数:
void kinit()- 在初始化的时候被调用。给 kmem 加锁,然后组织管理 一定范围 的物理内存。
void freerange(void *pa_start, void *pa_end)- 组织管理 一定范围 的物理内存。
void kfree(void *pa)- 按照指针地址清空 PGSIZE 字节大小的物理内存,并回收至 kmem(or freelist)。
- 在初始化的时候被调用,作用是把最开始的物理内存放置到 kmem 中(配合 freerange)。
void *kalloc(void)- 为调用它的进程提供一块 PGSIZE 大小的连续内存,或者说一个空页。
c. 为什么指导书提及的优化方法可以提升性能?
每个 CPU 核使用独立的链表可以在完成内存管理的前提下减少很大程度的竞争。不管是申请内存还是释放内存,都是优先在自己的 freelist 完成,这样比共享某个结构竞争少很多。
2 磁盘缓存
a. 什么是磁盘缓存?它的作用是?
(还是一块说)
由于对磁盘的读取非常慢,而内存的速度要快得多,因此将最近经常访问的磁盘块缓存在内存里可以大大提升性能(此时内存起到 cache 的作用)。Buffer Cache(也称为 bcache)就担任了磁盘缓存一职,它是磁盘与文件系统交互的中间层。
b. buf 结构体为什么有 prev 和 next 两个成员,而不是只保留其中一个?请从这样做的优点分析(提示:结合通过这两种指针遍历链表的具体场景进行思考)。
首先看一下它的基本结构:
struct {
struct spinlock lock;
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// head.next is most recently used.
struct buf head;
} bcache;这是预设好大小的,有一个头结点的双向循环链表。
优点 1:与单向链表相比,双向 + 循环为查找提供了良好的性能。
例子:比如要找指定节点的上一个节点,或者是从链表的最后一个节点开始之类的情况,单链表的性能很差。
| 找指定节点的上一个节点 & 时间复杂度 | 找最后一个节点 & 时间复杂度 | |
|---|---|---|
| 单向链表 | O(n) | O(n) |
| 双向链表 | O(1) | O(n) |
| 双向循环链表 | O(1) | O(1) |
具体到本次实验中,也就是 kernel/bio.c 中的代码:LRU 的部分。
// Not cached.
// **Recycle** the least recently used (LRU) unused buffer.
// diff from the former
for (b = bcache.head.prev; b != &bcache.head; b = b->prev)
{
// refcnt == 0 means unused
if (b->refcnt == 0)
{
b->dev = dev;
b->blockno = blockno;
b->valid = 0; // set valid 0, wait for virtio_disk_rw()
b->refcnt = 1;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}要从最后开始找,而且是从最后倒着找。
单向链表首先不能倒着找所以 FAIL,双向链表找到最后一个节点还需要把链表遍历完所以也不是很行,所以使用双向循环链表就很合适。
优点 2:为删除链表节点提供了很便利的方法。
双向链表的节点的删除,只需要把自己从链表中摘出即可;
void remove(struct buf *b)
{
b->next->prev = b->prev;
b->prev->next = b->next;
}而单向链表还需要遍历到该节点,再进行处理,这是很麻烦的。
// b_target must exist in the list
void remove(struct buf *head, struct buf *b_target)
{
struct buf *b;
// init: the prev is head (laugh)
struct buf *prev = head;
// deal with the head carefully
for (b = head->next; b != (void *)0; b = b->next)
{
if (b == b_target)
prev->next = b->next;
// record prev
prev = b;
}
}c. 为什么哈希表可以提升磁盘缓存的性能?可以使用内存分配器的优化方法优化磁盘缓存吗?请说明原因。
因为原先的设计是所有的 buffer 都被组织到 一条链表 中,因此如果有多个进程要使用 buffer,它们并发的请求只能被顺序地处理。通过哈希桶来代替链表,当要获取和释放缓存块时,只需要对某个哈希桶进行加锁,桶之间的操作就可以并行进行,提供并行性能。
不可以使用内存分配器的优化方法优化磁盘缓存,即不能为每个 CPU 分配属于自己的磁盘缓存区。
主要原因是多个进程间(或者说多个 CPU 间)访问磁盘同一块区域时会访问同一块缓存数据块(也就是缓存数据块是共享的);此外,一个磁盘缓存本身比较大,为每个 CPU 核都分配一个磁盘缓存显然会造成空间浪费(一块数据块存在于多个 CPU 核的磁盘缓存中,这是很浪费的)。
二 实验详细设计
内存分配器:Memory allocator
- 内存分配器做完之后的测试部分:Memory allocator - test
磁盘缓存:
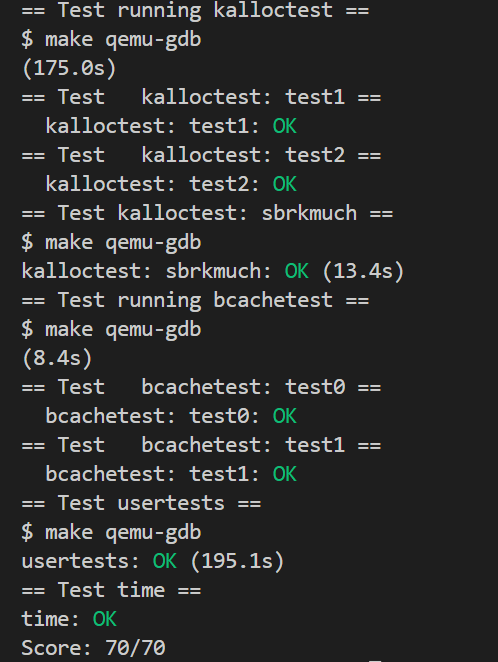
三 实验结果截图
貌似 grade 只能在 CPUS = 3 的情况下跑,用 CPUS = 8 就寄了。
如果电脑 CPU 性能太差,出现超时导致 FAIL 的问题。虽然如下的 grade 评测通过,但是可以看到 175.0s 和 grade_lab_lock 中的 timeout = 200 已经很接近了,这次评测成功只是偶然。你需要换一台更好的电脑哦。